

Introduction
If you have ever been involved in a postmortem call then you know the most popular root cause approach is deny deny deny 😊. All joking aside, as a problem manager, the Root Cause Analysis (RCA) is more than just asking "why" repeatedly. It's a structured approach or dare I say, it's an art to problem-solving that can transform how organizations handle incidents.
Lets walk through 3 popular RCA methods: 5 Whys, Ishikawa, and Fault Tree Analysis.
*Note: The following article only covers RCA methods and does not cover the entire RCA process, including identifying contributing factors such as monitoring, MTTR, MTTD, etc.*
Case Study 1: The Recurring Network Outage
The Scenario
A financial services company experienced intermittent network outages every Friday afternoon, impacting customer transactions.
The Analysis: 5 Whys Technique
Why 1: Why did the network go down?
- Because the network bandwidth was maxed out
Why 2: Why was the bandwidth maxed out?
- Because of a spike in backup processes
Why 3: Why was there a backup spike at that time?
- Because all department backups were scheduled for Friday 2 PM
Why 4: Why were all backups scheduled simultaneously?
- Because there was no backup schedule coordination between departments
Why 5: Why wasn't there coordination?
- Because there was no centralized backup policy managementPreventative Actions
Implementation of a staggered backup schedule and centralized backup policy reduced network load by 60% and eliminated the outages.
Case Study 2: The Mysterious Application Crash
The Scenario
A critical business application would crash unpredictably, with no clear pattern in the logs.
The Analysis: Ishikawa (Fishbone) Diagram
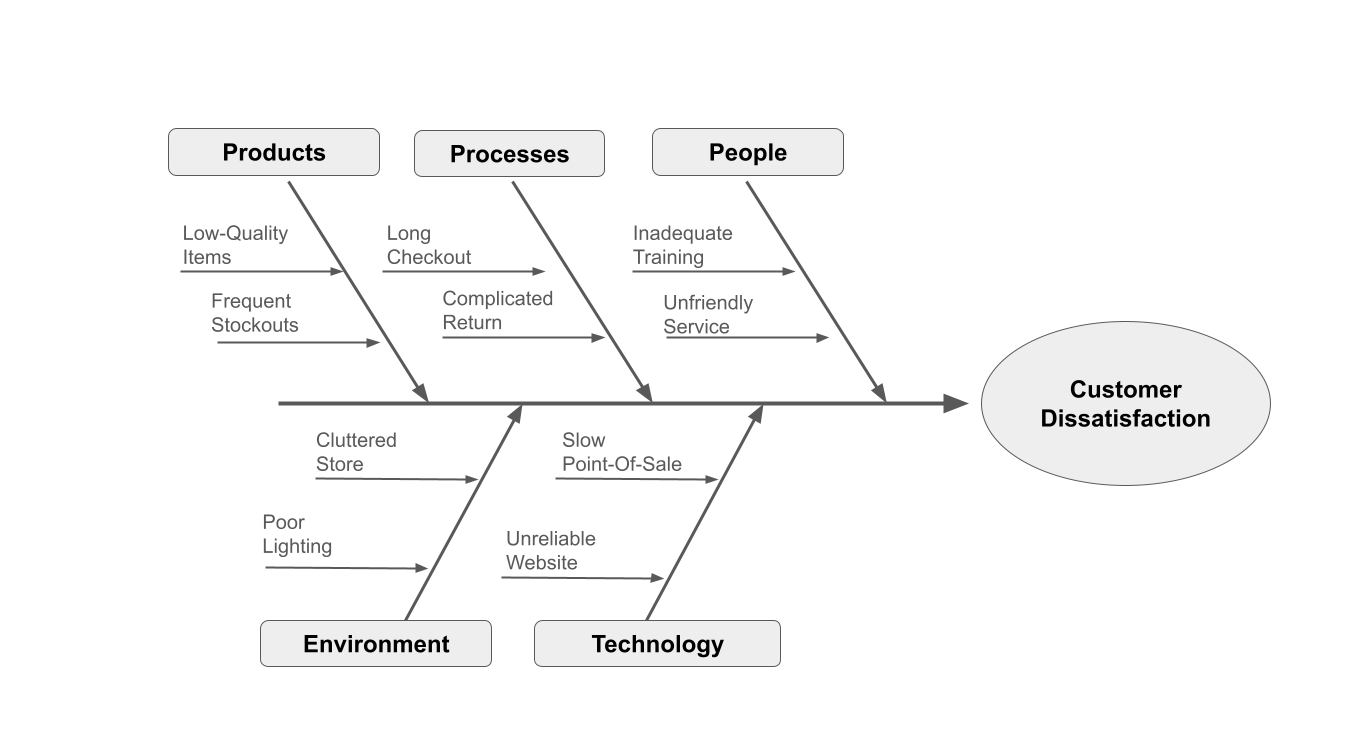
The fishbone analysis revealed multiple contributing factors:
- Technology: Memory leaks in the application
- Process: No regular process for memory cleanup
- People: Junior developers unaware of memory management best practices
- Monitoring: Memory threshold alerts went to the wrong team
Preventative Actions
A comprehensive list of preventative actions including code optimization, automated memory management process, new alert email distribution list, and team training resulted in 99.9% uptime and quicker responses in the event of future issues.
Case Study 3: The Payment Processing System Failure
The Scenario
A financial services company experienced recurring system failures in their payment processing platform, leading to service disruptions and customer dissatisfaction.
The Analysis: Fault Tree Analysis
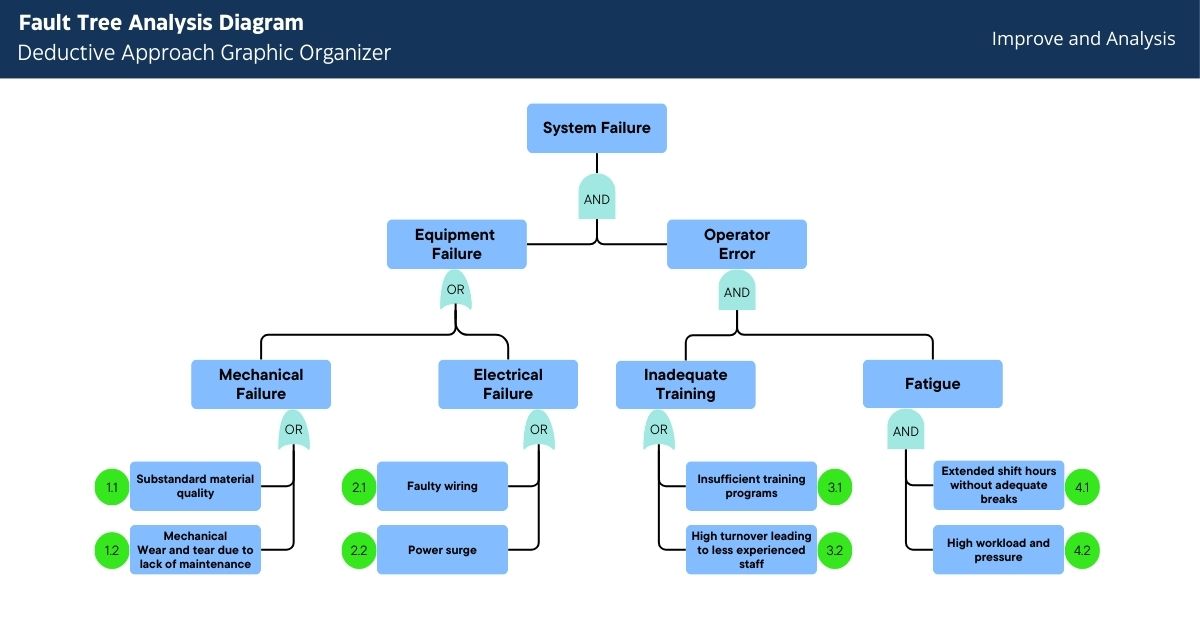
The Fault Tree Analysis revealed that system failures occurred when both equipment failures and operator errors were present:
- Equipment Failures (OR gate):
- Mechanical Failures:
- Substandard material quality in server components
- Mechanical wear and tear due to lack of maintenance
- Electrical Failures:
- Faulty wiring in the data center
- Power surges affecting critical systems
- Mechanical Failures:
- Operator Errors (AND gate):
- Inadequate Training:
- Insufficient training programs for new staff
- High turnover leading to less experienced staff
- Operator Fatigue:
- Extended shift hours without adequate breaks
- High workload and pressure during critical incidents
- Inadequate Training:
Preventative Actions
Based on the FTA findings, we would propose the following preventative actions:
- Equipment Improvements:
- Implemented strict quality control for hardware components
- Established regular maintenance schedules
- Upgraded electrical systems with surge protection
- Conducted thorough wiring inspections and repairs
- Operator Support:
- Developed comprehensive training programs
- Implemented better shift management
- Increased staffing levels to reduce workload
- Created mandatory break schedules
Key Takeaways
- Choose the right RCA tool for the problem complexity
- Involve all stakeholders in the analysis process
- Document findings and solutions thoroughly
- Implement preventive measures, not just fixes
Conclusion
There is more than one way to skin a cat and the same goes for RCA. At the end of the day, an effective RCA if done properly, pinpoints the true root cause of the incident and identifies preventative actions that will reduce the likelihood of the incident occurring again and reduce the impact of the incident if it does occur. By applying these techniques appropriately, you can transform reactive problem-solving into proactive problem prevention.